
Small models, big impact: SLMs vs. LLMs
Small language models are entering the big leagues! In this piece, I look at several exciting case studies to examine how SLMs are packing a punch against their larger counterparts.

HuggingFace CEO and co-founder Clem Delangue has made a bold claim that 2024 will be the year of small language models (SLMs). I couldn’t agree more!
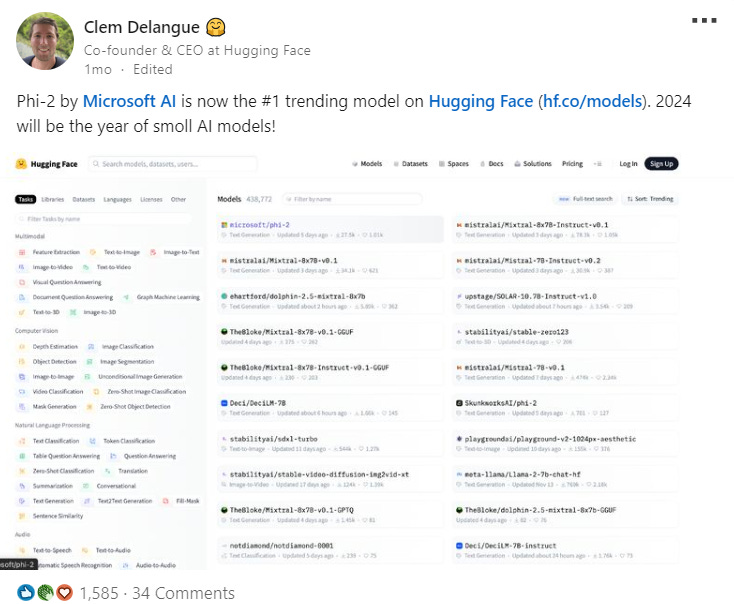
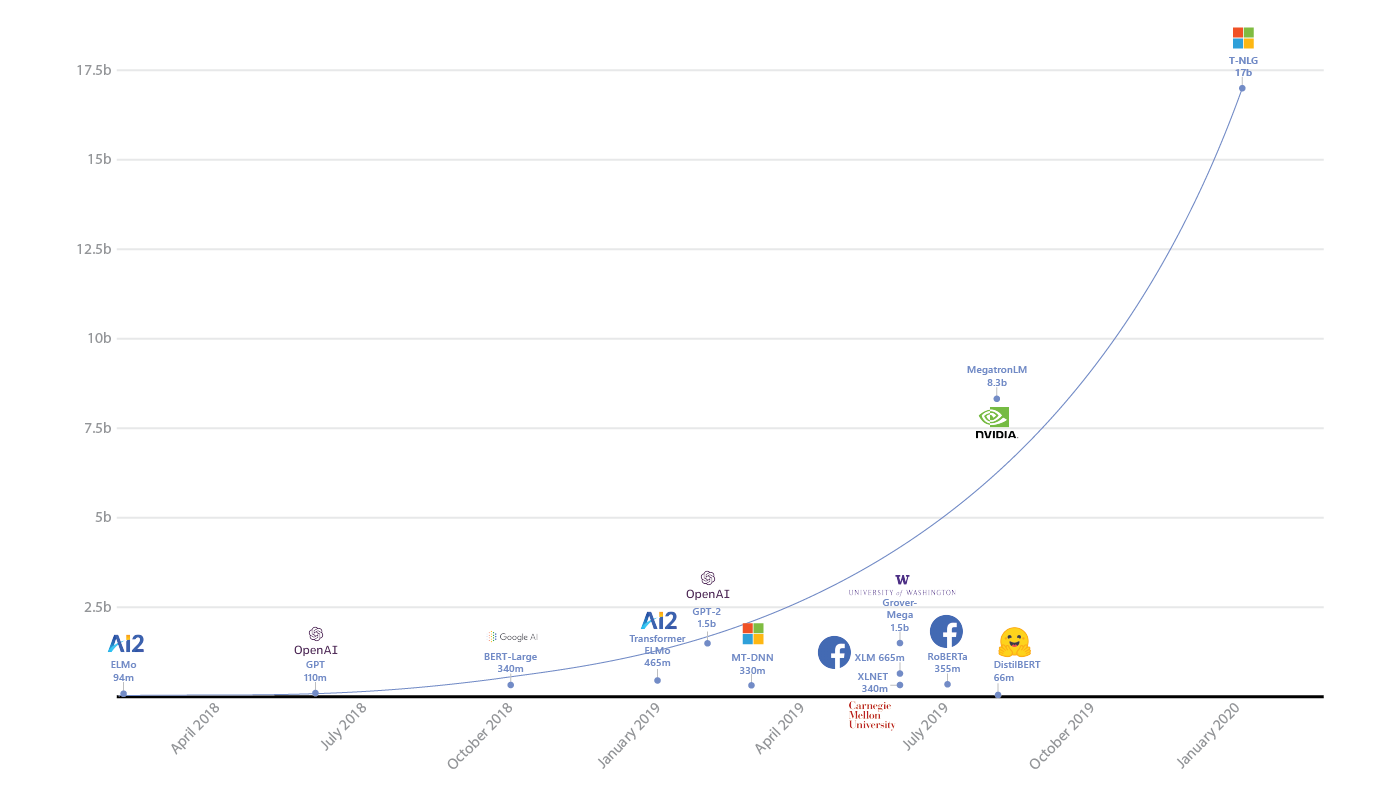
As I highlighted last month in my article on recent developments in the open vs. closed source model debate, Mixtral MoE 8x7B has shown that SLMs can be at-par and at times even more capable than much larger proprietary models. Additionally, in a world where large language models (LLMs) are getting so big that they are unwieldy (chart below), not only can SLMs credibly compete on performance against LLMs, their compact sizes can unlock added benefits that make them a better option for particular use cases. In fact, Delangue goes so far as to suggest that SLMs could cover 99% of use cases!
In this piece, I dive into several case studies to examine the power of small models and their incremental advantage vectors:
Bigger isn’t always better: Mistral-7B, Zephyr-7B, Phi-2
Faster, more secure, and edge-efficient: DistilBERT
Cost and customizability of SLMs in vertical AI: BloombergGPT-50B vs AdaptLLM-7B
SLMs as a panacea to training data limitations: TinyStories-28M, Phi-1, Orca-2
I. Bigger isn’t always better: Mistral-7B, Zephyr-7B, Phi-2
While Mixtral MoE 8x7B is impressive, it isn’t the only example of SLMs outperforming LLMs. Prior to their MoE model, Mistral released Mistral-7B. At the time of launch, Mistral-7B was the most powerful language model of its size that could outperform much larger Llama 2 and Llama 1 models on various benchmarks:

Building on this work, HuggingFace H4 released Zephyr-7B by fine-tuning Mistral-7B on a mix of publicly available and synthetic datasets using a method called Direct Preference Optimization. Zephyr-7B-β then became the highest ranked 7B chat model across MT-Bench and Alpaca benchmarks (exhibit below). Most impressively, it outperformed both larger open-source as well as closed source LLMs such as GPT-3.5-turbo (~25x larger) by Alpaca benchmarks.

The preceding examples are illustrations of how startups have been spearheading big contributions on the small model front. But Big Tech is not sleeping on the small model trend either. Late last year, Microsoft launched Phi-2, a 2.7B SLM that is engineered for efficiency and adaptability in both cloud and edge deployments. Phi-2 demonstrates outstanding reasoning and language understanding capabilities, showcasing state-of-the-art performance among other SLMs with less than 13 billion parameters. More impressively, Microsoft claims that Phi-2 matches or outperforms much larger models such as Llama-2-70B and Google Gemini Nano 2 on complex benchmarks across logical reasoning, common sense, mathematical reasoning, and language understanding:

II. Faster, more secure, and edge-efficient: DistilBERT
Section I covered exciting developments in SLM performance capabilities. Let’s now look at some benefits of smaller models beyond performance quality. DistilBERT, which was created using knowledge distillation to reduce the size of a BERT-base model by 40%, presents an interesting case study for this discussion:
Speed: Even though DistilBERT is significantly smaller than BERT-base, it retains 97% of BERT performance around language understanding abilities while being 60% faster, making DistilBERT a better option for applications where speed is critical. Researchers also showed that DistilBERT, which only weighs 207MB and can be further reduced with quantization, is small enough to effectively run on the edge, and the average inference time of DistilBERT on an iPhone 7 Plus is 71% faster than BERT-base. In general, smaller models that operate on edge devices show lower latency since data is not transferred to the cloud for inference. This is key in use cases where near-instant (milliseconds) responses are required such as in vehicle autonomy, safety-critical automation, and medical imaging.

Security and privacy: The fact that SLMs like DistilBERT can be easily operated on the edge could also be a core benefit (and perhaps even a necessity) in specific edge-first use cases within highly regulated industries or fully isolated environments often found in the defense, healthcare, or financial services sector. Running SLMs at the edge can in theory increase the guarantee of privacy since sensitive information is not kept on servers, reducing the risk of breaches or unauthorized access. But more generally, SLMs, with smaller codebases and fewer parameters, tend to be intrinsically more secure because they have fewer attack surfaces. For context, DistilBERT has 66M parameters while BERT-base has 110M parameters.
Safety: From an AI safety angle, since SLMs are trained on small, curated datasets, this control over data could in theory help to reduce the risks associated with biased or malicious data. It is also easier to run risk assessments or observe transparency with SLMs given their less complex structure (for instance, DistilBERT only has 6 transformer layers, the BERT base model has 12).
III. Cost and customizability of SLMs in vertical AI: BloombergGPT-50B vs AdaptLLM-7B
This SLM vs LLM discussion has also been heating up in vertical AI. Last year, Bloomberg launched BloombergGPT, a 50-billion parameter language that was trained from scratch on a 363 billion token dataset based on Bloomberg’s finance-specific data sources and a 345 billion token general purpose dataset. Based on this training, the aspiration was for BloombergGPT to significantly outperform similarly-sized models on finance-specific tasks without sacrificing performance on more general benchmarks:

This blended approach to train an LLM from scratch on both domain specific as well as general data sources was notable at the time, since domain-specific LLMs had so far either been trained exclusively on domain-specific data sources or adapted from a very large general purpose model to domain-specific tasks. However, such a training technique came with great costs, especially for compute resources. Bloomberg reportedly required 1.3 million hours of training time for BloombergGPT on Sagemaker using 512 Nvidia A100 GPUs (40GB)! For many organizations, putting large models in production is often impractical due to compute costs and sometimes outright impossible due to GPU shortage.
In the 6 months that followed, motivated by the need to create more cost-effective options for domain-specific AI, another team from Microsoft released AdaptLLM, which trained domain-specific models via reading comprehension text. This team showed how a smaller AdaptLLM-7B model could achieve competitive performance on domain-specific tasks in finance to larger models such as BloombergGPT-50B (chart below) at a significant fraction of the cost and time. Additionally, the Microsoft team demonstrated that this method opens the potential for customizability across different domains including biomedicine and law.

IV. SLMs as a panacea to training data limitations: TinyStories-28M, Phi-1, Orca-2
Beyond compute resource considerations highlighted in Section III, training data (both in terms of volume and reliability) has been identified as a potential real-world constraint for machine learning:

Thankfully, smaller datasets as well as synthetic datasets have been shown to satiate the training of SLMs:
In “TinyStories”, Microsoft researchers trained SLMs on a synthetic dataset of short stories that only contained words that a toddler would understand. Despite their size and simple architecture, these models still produced fluent and consistent stories with several paragraphs that were diverse and had near perfect grammar. The study also showed that GPT-4 (as an evaluator) preferred stories generated by a 28M parameter SLM trained on TinyStories to those generated by GPT-XL (1.5B parameters).
In “Textbooks are all you need”, Microsoft researchers trained Phi-1 (a transformer-based model with 1.3B parameters) for 4 days on 8 A100s, using a selection of 6B tokens of “textbook quality” data from the web and 1B tokens of synthetically generated textbooks and exercises with GPT-3.5. Despite its small scale, Phi-1 achieved state-of-the-art performance on Python coding among existing SLMs (specifically pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP). These researchers subsequently published “Textbooks are all you need II” detailing Phi-1.5. These bodies of work set the foundation for Phi-2 discussed in Section II.
Orca 2 (which comes in 7B as well as 13B versions) was developed by Microsoft by fine-tuning Meta’s Llama-2 on curated, high-quality synthetic data. Orca 2 achieved competitive performance levels to larger models, especially in zero-shot reasoning tasks:

Source: Mitra et al., “Orca 2: Teaching Small Language Models How to Reason” (11/18/23)

The SLM movement will grow bigger
These are just a handful of case studies demonstrating the power and benefits of SLMs. So many more exciting examples have been popping up all over the world recently, involving different languages and use cases. With AI innovation accelerating at rapid speed, novel techniques like QLoRA are constantly being developed to push the limits on SLMs, allowing them to become better, cheaper, and faster. I’m excited for this momentum since I wholeheartedly believe that future AI innovation cannot be driven solely by increasing parameters. Additionally, small model developments can further unlock AI proliferation by enabling organizations, particularly startups with limited resources, a practical way to leverage AI for their use cases.