
Unwrapping OpenAI’s o3
Christmas came early for the AI community this year as OpenAI unveiled its newest frontier model o3 last Friday. My colleague Lance and I unpack what this might mean for the applied AI landscape.

Ahead of o3’s public release, my colleague Lance Co Ting Keh (check out his blog here) and I riffed on what this might mean for the applied AI landscape. This post captures a quick summary of our discussion.
Christmas came early for the AI community this year as OpenAI unveiled its newest frontier model o3 last Friday. o3 set the AI world abuzz because of its unprecedented performance across domain-specific and general reasoning benchmarks. o3 not only significantly outperformed its predecessor o1 on all benchmarks, demonstrating an incredibly rapid development cycle for reasoning models, but also seemingly surpassed top human intelligence in particular domains:

Software engineering: 71.7% from o3 on SWE-bench vs 48.9% from o1
Competition code: o3 achieved a 2727 Codeforces rating which is equivalent to the 175th best competitive human coder on the planet
Competition math: o3 scored 96.7% on the 2024 American Invitational Mathematics Exam, missing just one question
PhD-level science: o3 hit 87.7% on GPQA diamond (a set of graduate-level biology, physics, and chemistry, questions). To put this into context, OpenAI states that expert PhDs typically attain 70% in their relevant field.
Frontier Math: o3 set a new record of 25.2% on EpochAI. No previous model has exceeded 2%.
Adaptive general intelligence: o3 surpassed previous records on ARC-AGI (designed to evaluate an AI’s ability to adapt to tasks without relying on pre-trained knowledge), scoring 75.7% on the semi-private eval in low-compute mode and 87.5% in high-compute mode.
Some critics are skeptical of these reported results. But overall, many agree that o3 marks a major milestone in AI capabilities, and is pushing the boundaries on what it means to build appropriate and rigorous benchmarks for AI reasoning. As François Chollet, creator of ARC-AGI, highlights:
“This is a surprising and important step-function increase in AI capabilities, showing novel task adaptation ability never seen before in the GPT-family models. For context, ARC-AGI-1 took 4 years to go from 0% with GPT-3 in 2020 to 5% in 2024 with GPT-4o. All intuition about AI capabilities will need to get updated for o3.”

o3 is undoubtedly impressive, but as venture capitalists, Lance and I are most interested in how AI innovations transcend a theoretical setting and make it into practical use cases. In the real world, performance alone is not enough. Cost matters as consumers and enterprises calculate their ROI for deploying AI solutions. Currently, it costs a whopping $17-$20 per task to run o3 in low-compute mode, and inference costs could scale to thousands of dollars per task in high-compute mode since the amount of compute needed for o3’s high-compute configuration is roughly 172x the low-compute setting. Suffice to say, it’s currently very expensive to run o3, and this could be cost prohibitive or unsustainable in particular situations.
Latency is another key factor to consider in an applied AI setting. As I wrote previously, OpenAI’s latest models have shifted from an emphasis on pre-training to inference-time scaling. This has been a hot topic in the AI world recently, with AI luminary Ilya Sutskever declaring that “pre-training as we know it will end” during his talk at NeurIPS earlier this month. o3 models employ a “private chain of thought” where the model internally deliberates and plans before delivering a response. While such “thinking” enhances the model’s performance reliability, this process incurs latency as o3 needs to take time to arrive at its solution. o3 comes with the ability to adjust its reasoning time since models can be set to low, medium, or high compute.
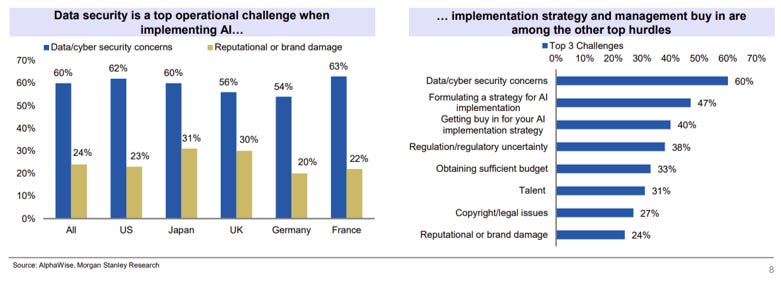
Last but not least, ensuring security, safety, and governance, is critical in an applied setting. These vectors are table-stakes for enterprise adoption (chart below). We note that o3 is not yet open to the public, and early access is currently reserved for safety and security researchers.
So what might all of this mean for the AI application landscape in the near term?
AI agents: As highlighted above, o3 and other CoT models are currently expensive at inference and are unlikely to be used for sub-task/tool-calling parts of the stack today. However, AI agent companies should still think about how to incorporate these frontier models thoughtfully (for instance, developing framework architecture to call on such models less frequently) and/or for the right use cases (perhaps planning) since such frontier models could move the needle significantly in terms of downstream task performance. Longer term, reasoning models like o3 could completely change the meta-agent landscape (i.e. where agents prompt other agents).
Real-time tasks: Given the latency limitations of reasoning models, their adoption may be limited in settings where real-time reactivity is required, such as fraud detection and database querying, or conversational use cases like customer support.
Tasks involving limited context length: Use cases that are bound in performance by context length (such as enterprise search or information retrieval) can perhaps benefit more from deduplicating and minimizing context because of better generalization in models like o3.
AI code gen and developer tooling: On the performance side, o3 has shown breakthrough performance on software engineering and coding benchmarks. This ushers in new implications to the entire AI code gen and developer landscape. Imagine a world where organizations could now have an L7 AI engineer at their fingertips! That said, the cost and latency limitations of o3 may make it inappropriate for quick and iterative coding use cases right now. But organizations should think about higher-level use cases where escalating to o3 clears the threshold of value. Startups could also design product experiences around this, such as no-code app builders or end-to-end full stack builders, to “productize” around the trade-offs of AI.
Vertical AI: While base models become better at generalization and reasoning, these come with associated trade-offs in speed and costs. Verticals, such as legal, where founders can build products around these limitations should experience early and outsized benefit from the new wave of reasoning models.
Data tools for reasoning models: CoT labeling is key to attaining high levels of performance under this new model paradigm. Companies should pay attention to data tools such as labeling or synthetic data focused on CoT.
Scientific research: This year, both the Nobel prizes for Physics and Chemistry were awarded to work related to artificial intelligence. o3’s outstanding results, especially in technical domains like science and math, adds to this exciting news since o3 could help to power a broader acceleration in scientific research and healthcare AI.
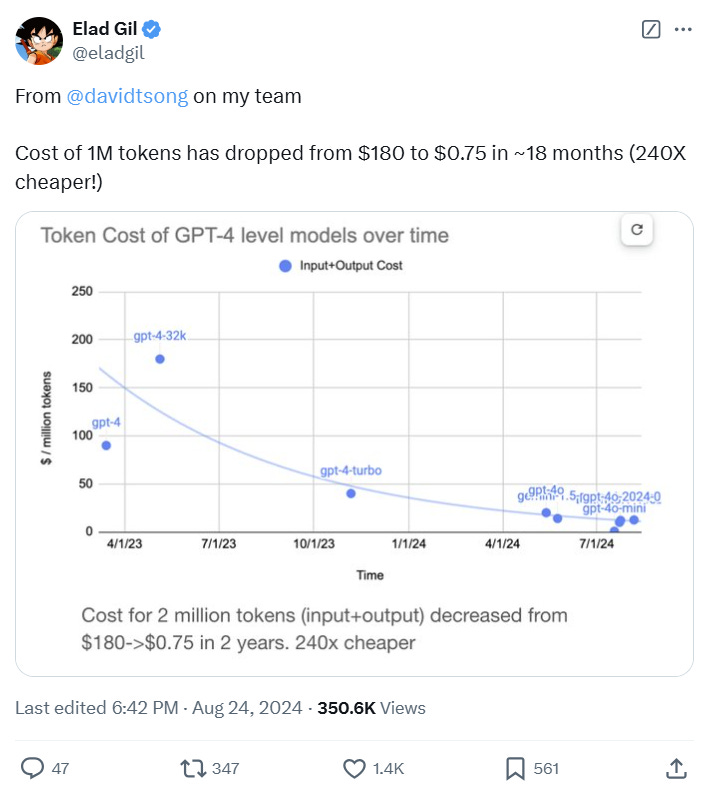
Longer term, the hope is that we’ll see a trend of expeditious cost reductions for reasoning models, similar to what was observed in the LLM world (exhibit above), which will further unlock the potential of such models in an applied setting. But for now, while o3 isn’t perfect, its unveiling is a powerful prelude to more exciting things to come in the new year. As Jim Fan aptly states “Huge milestone. Clear roadmap. More to do.” Merry Christmas!