
AI’s Linux Moment (Chapter 2): Recent highlights of the open-source vs. closed-source model debate
So much has happened in the past 6 months since I first wrote about the open vs closed model race. In this follow-up, I cover how recent developments continue to fan the flames in this heated battle.

Half a year ago, I wrote about AI’s Linux moment and the challenge posed by open-source models to their more well-funded closed-source peers. The pace of AI innovation is accelerating ever so quickly that multiple notable events and new players have been introduced to this debate just within the last six months. These developments have prompted me to pen this follow-up piece which covers recent updates in this dynamic battle:
Open-source continues to rapidly close the performance gap with closed-source models
Knowledge sharing environment has become less transparent as commercialization stakes get higher
“Security through obscurity” vs. “Security through openness” remains a central point of contention
Emerging regulatory landscape and its impact on both factions
A quick note on semantics before we dive in: There are various definitions and interpretations for “open-source”. For the purposes of this article, I use a broad definition of the term to refer to models released with widely available weights:

I. Open-source continues to rapidly close the performance gap with closed-source models
As I highlighted in my first article on this battle, a Google researcher asserted in the viral “We Have No Moat, And Neither Does OpenAI” memo from May 2023 that open-source players are narrowing in on quality to closed-source players. Citing Vicuna-13B as an example, the researcher goes on to predict that open-source will eventually outcompete proprietary models on various fronts like speed and cost to train. In the months since, new examples such as Llama-2 (released in July 2023) and Mixtral 8x7B (released in December 2023) have emerged, reinforcing the point that open-source models are catching up quickly to their closed-source peers:

While open-source players do not yet outperform the capabilities of the latest proprietary models like GPT-4, the salient point is that they can get very close on performance and come with other advantages such as cost savings and improved inference latency. These added benefits can make open-source a better option in some contexts. For example, the team at Anyscale ran an experiment that showed Llama-2 is about as factually accurate as GPT-4 for summarization while being significantly cheaper:

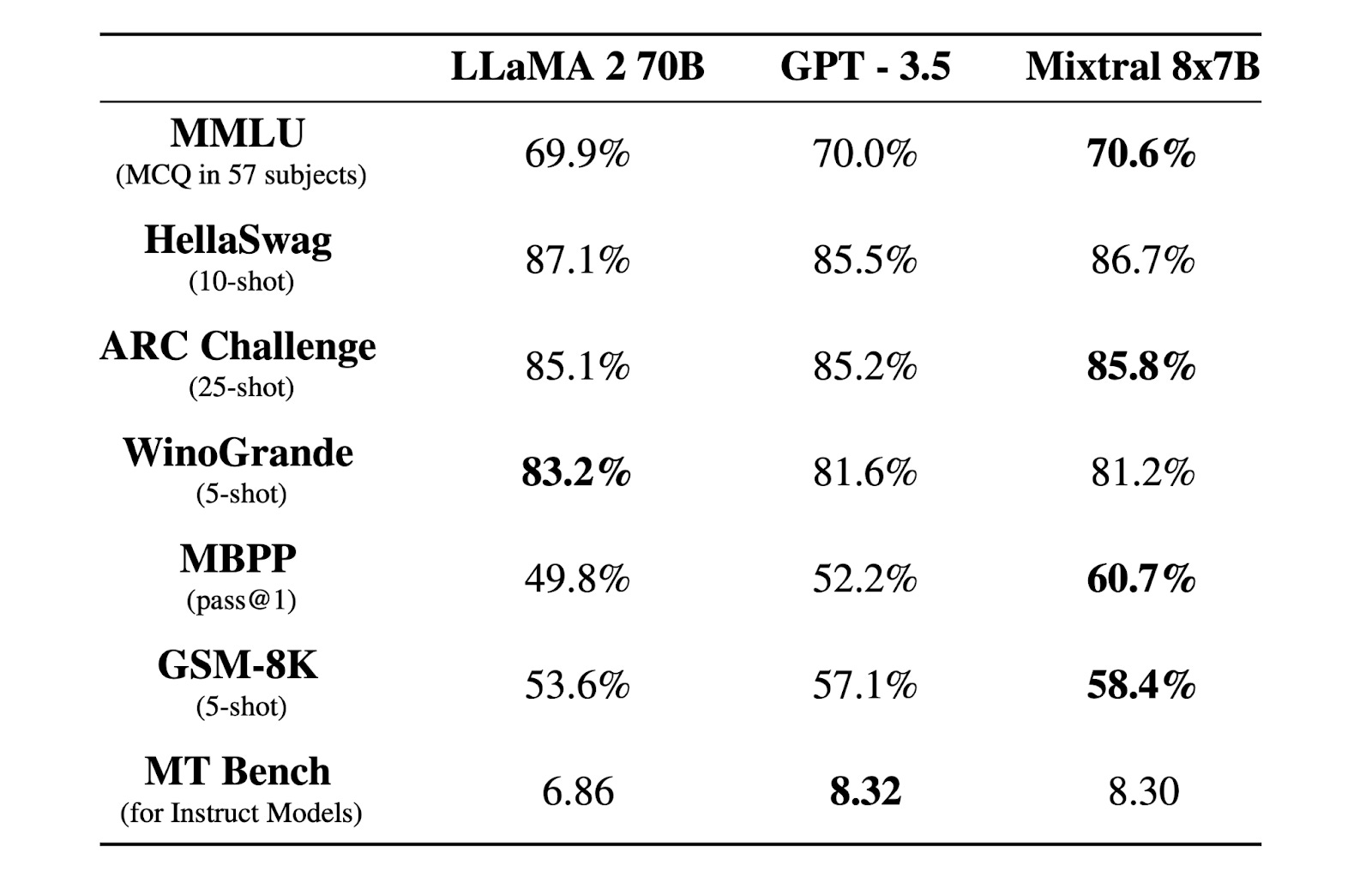
Mixtral 8x7B is another interesting case study, given it is a small and efficient sparse model that can run on a single GPU, yet still performs above or to par with much larger proprietary models such as GPT-3.5 on various benchmarks (exhibit below). Mixtral 8x7B captivated the open-source community as it utilizes Mixture-of-Experts, which is the same architecture rumored to be used by GPT-4 (more on this in the next section). Furthermore, if Scaling Laws demonstrate diminishing returns, it could help open-source catch closed-source even faster.
II. Knowledge sharing environment has become less transparent as commercialization stakes get higher
The stakes are high to dominate the AI model layer. Unsurprisingly, as open-source continues to make huge strides in closing the capability gap, closed-source models have become… even more closed. For instance, OpenAI shared the architecture and training details for GPT-1, GPT-2, GPT-3, and InstructGPT, in their respective technical papers, but decided not to disclose this information for GPT-4. OpenAI was clear in its rationale for this decision, noting in GPT-4’s technical report that:
“Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.”
This move was met with scathing criticism across various stakeholders in the AI community, from researchers to startup leaders. Since a meme speaks a thousand words, here is my favorite hot take:
The criticism isn’t simply about such behavior being detrimental to open research or academic integrity. There are consequential trust and safety implications that come with reduced transparency. Identification of model biases, understanding limitations, as well as validation of performance claims, all become more difficult when code cannot be verified and results cannot be replicated. In a recent example demonstrating this point, many of these issues came to light as the community actively hypothesized and investigated root causes for GPT4’s “lazy” behavior:

Reflecting on the irony of OpenAI powering “closed AI”, Stanford HAI launched The Foundation Model Transparency Index (chart below) in October 2023, emphasizing that:
“Less transparency makes it harder for other businesses to know if they can safely build applications that rely on commercial foundation models; for academics to rely on commercial foundation models for research; for policymakers to design meaningful policies to rein in this powerful technology; and for consumers to understand model limitations or seek redress for harms caused.”

OpenAI’s precedent has set a clear tone for the industry. Google followed suit when it launched PaLM 2 in May 2023, noting that “further details of model size and architecture are withheld from external publication”. Anthropic has not published any technical reports for Claude (more on this later in the next section). On the vertical AI side, Bloomberg dedicated an entire section addressing “openness” in its technical paper for its domain-specific BloombergGPT model (launched in March 2023), eventually concluding that “each decision reflects a combination of factors, including model use, potential harms, and business decisions....we err on the side of caution and follow the practice of other LLM developers in not releasing our model”.
Such behavior has not just been perpetuated within the realm of closed-source providers. Even some open-source players are moving to become more guarded. A case in point: while Meta's first Llama paper detailed the training dataset that was used to train the models, the Llama-2 paper did not disclose this information.
III. “Security through obscurity” vs. “Security through openness” as a central point of debate
Beyond the rationale of intellectual property protection discussed in the last section, closed-source companies are also pointing to security implications as additional justification for shutting off knowledge sharing. While addressing why Claude’s model weights are a highly-protected trade secret, a recent interview with Anthropic’s CISO Jason Clinton underscored that:
“He knows some assume the company’s concern over securing model weights is because they are considered highly-valuable intellectual property. But he emphasized that Anthropic, whose founders left OpenAI to form the company in 2021, is much more concerned about non-proliferation of the powerful technology, which, in the hands of the wrong actor, or an irresponsible actor, ‘could be bad.’”
Open-source proponents are incensed by this “security through obscurity” premise as many of them believe wholeheartedly in the inverse — that openness can help to promote security. The argument underpinning this belief is that putting a technology in as many hands as possible for review can serve to reduce risks. For instance, Stanford HAI pointed out in their brief on “Considerations for Governing Open Foundation Models”:
“Though open code models could improve the speed and quality of offensive cyberattacks, it appears that cyber defenses will also improve. For example, Google recently demonstrated that code models vastly improve the detection of vulnerabilities in open-source software. As with previous automated vulnerability-detection tools, widespread access to open models for defenders, supplemented by investment in tools for finding security vulnerabilities by companies and governments, could strengthen cybersecurity.”
IV. Emerging regulatory landscape and its impact on both factions
This discourse on AI security has carried over into the regulatory sphere. As I mentioned in my 2023 wrap-up, last year was a notable year for AI regulation as policymakers around the world increased scrutiny over AI governance:

A key piece of US AI policy published last year was President Biden’s Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. This order served to establish wide-ranging guidelines for AI use and governance. Open-source proponents were particularly vocal in their response to the Executive Order, given the potential disproportionate impact of the Order on the open-source community. These proponents, ranging from academics to founders to investors, have even submitted a letter to The White House, articulating concerns around:
Reporting requirements: particularly around how the Executive Order's overly broad definitions of “AI” and "dual-use models" would put undue restrictions on open-source, and that these requirements are “really suited to companies with significant resources, like the major technology incumbents”
AI safety and security debate: advocating that open-source software is akin to a peer-reviewed publication since a large group of individuals can help to identify and fix “potential flaws, vulnerabilities, and points of exploitation” versus “in proprietary systems, vulnerabilities may linger undetected, or worse, detected only by bad actors who go searching for these weaknesses in order to exploit them”
Market competitiveness: highlighting that open-source helps to reduce monopoly and foster competition, since “it guarantees that the algorithms shaping our society are transparent, accountable, and subject to modification by a diverse array of individuals with different insights and areas of expertise, rather than an elite few”
With regard to market competitiveness, the letter makes a stand that “regulation that allows several large tech corporations to capture the market will ensure only a select few own and operate a repository of human knowledge and culture”. Building on this point, one of my favorite talks from last year was Bill Gurley’s “2,851 Miles” presentation, where he draws attention to the impact of regulatory capture on innovation, and why incumbents are all for AI regulation since they are poised to reap outsized benefits. As I’ve written and tweeted previously, mega cap strategics are highly intertwined with many closed-source AI incumbents, which may further explain some of the dynamics in the current push for regulation:

May the force be with open-source
In a time when closed-source AI is receiving more support from the Big Tech Empire than ever before, the open-source Rebel Alliance is showing no signs of backing down. Open-source AI is striking back with tremendous force, with many new participants joining the alliance — there are now over 400k models listed on HuggingFace (up from ~100k at the start of 2023) as the community strives to keep models and datasets easily accessible to all:

Open-source plays an invaluable role in fostering innovation, but beyond this, as a venture capitalist, I’m most excited about open-source because it facilitates the democratization of AI access. Not every startup has the resources to invest in capital intensive foundational model projects, hire an army of AI/ML talent, or afford closed-source options. Nor does every startup, especially those within the application layer, want to prioritize foundational model capabilities as a differentiator since they may want to focus on other parts of their competitive advantage. Open-source provides increased access, flexibility, and customizability, to foster vibrancy across the startup ecosystem, and for that I salute the open-source alliance.